You’re using AI tools every single day. There’s a problem you don’t even know about. Every time you have a long conversation with an AI, it’s quietly running out of memory. The longer the chat, the slower it gets, the more it forgets, the worse the answers, and the companies running these tools are paying a fortune just to keep up. That changes right now. Large language model (LLM) does not need more power to be faster. It just needs to remember smarter, that’s exactly google did with TurboQuant
Google just dropped something called TurboQuant, and I’m going to break down exactly what it is, why it matters to you, and what’s coming next.
Today AI model rely on something called KV cache, Basically a memory system that stores past information so the model doesn’t have to recompute everything again. But here the problem, memory is huge. to solve the google launch turboquant.
How TurboQuant works ?
Google Blog – TurboQuant Blog
The main goal here is tackle the KV cache.
If you aren’t in the weeds of LLM infrastructure, the KV cache is basically the “working memory” of a model. Every time you have a long conversation, the model has to store every word that came before so it doesn’t lose the thread. The problem? That memory is a total resource hog. It eats up VRAM faster than almost anything else. TurboQuant is designed to shrink that footprint to almost nothing without the model losing its mind—or its accuracy.
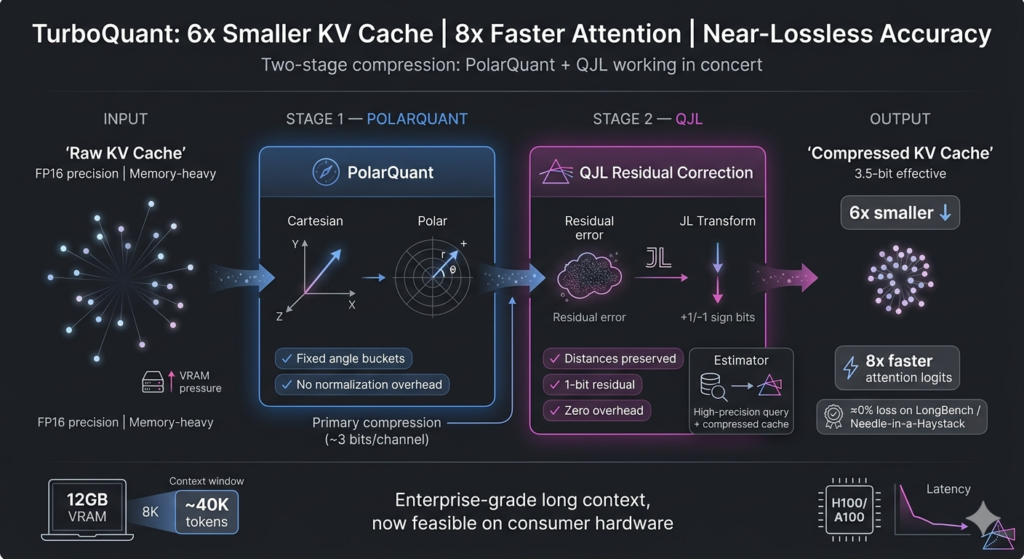
It does this through a two-step dance that handles both KV cache and vector search with some pretty slick math.
- The Heavy Lifting: PolarQuant- First, you have the PolarQuant stage. This is where most of the compression “budget” goes. See, data inside these models is usually a mess of precise decimals—vectors that are all over the place. If you try to compress them as-is, you get massive errors.
TurboQuant starts by “randomly rotating” these vectors. Think of it like shaking a bag of tangled coat hangers until they all lay flat and parallel. Once the geometry is simplified, it’s much easier to apply a standard quantizer. If you’ve ever seen a JPEG or listened to an MP3, you’ve used quantization; it’s just the process of mapping those infinite, messy decimals to a small, tidy set of integers. PolarQuant uses the bulk of its bits here to capture the “core” of the original vector.
- The Clean-Up Crew: QJL – But even the best rotation leaves some junk behind. There’s always a tiny bit of “noise” or error left over from that first squish. If you ignore it, that error compounds, and the model starts hallucinating or losing its “attention” score accuracy.
This is where the QJL algorithm comes in. It’s the “error-checker” of the system. It uses a tiny, residual amount of power—just 1 bit—to look at the leftover bias from the first stage and neutralize it. It’s like a high-end audio track where a tiny sub-file tells the speakers exactly how to fix the static in the background. By eliminating these hidden errors, the final attention score stays sharp.
The result is pretty wild. You get a massive reduction in model size with basically zero accuracy loss. It’s a mix of clever geometry and a 1-bit “undo” button for errors.
Look, the tech itself is genuinely clever. Even with the benchmarking drama, the engineering here is a real win for anyone trying to run huge models on limited hardware. We’re moving toward a world where your phone can remember a 50-page document without breaking a sweat, and this is one of the engines getting us there.
Anyway, that’s the gist. To really see how this scales, you have to look closer at how QJL and PolarQuant play off each other in a live environment. It’s a delicate balance, but when it works, it’s arguably the most efficient way we have to bridge the gap between “massive model” and “limited memory.”
QJL: The zero-overhead, 1-bit trick
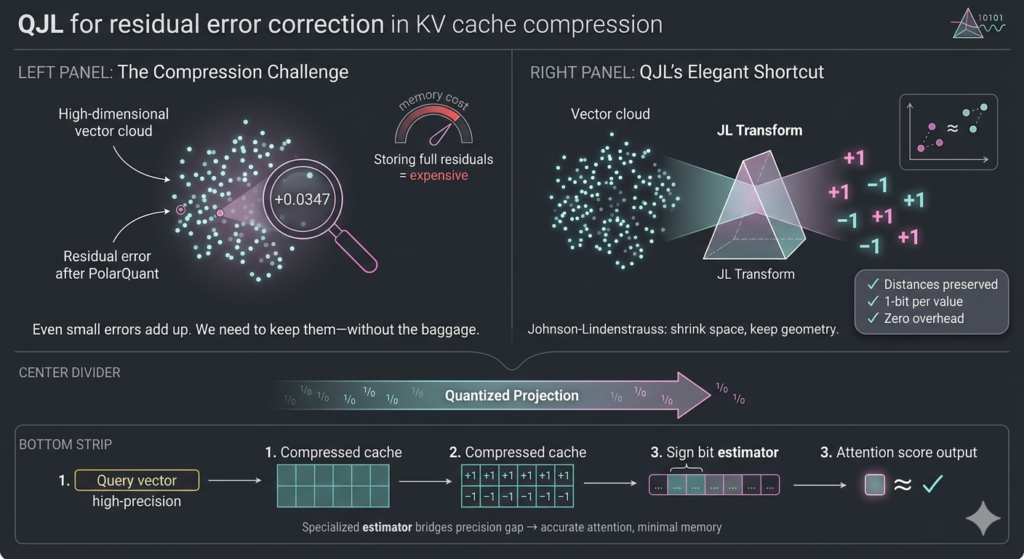
Compressing high-dimensional vectors down to basically nothing usually sounds like a fast track to model hallucinations. But QJL actually pulls it off, and the trick is pretty elegant. It leans on a math staple called the Johnson-Lindenstrauss Transform. Think of it as a controlled squeeze: it takes sprawling, complex data and forces it into a much tighter space without wrecking the actual distances between points. The geometry survives the trip.
Then it strips everything else away. Every resulting number gets boiled down to a single sign bit. Just +1 or -1. That’s the whole representation. You end up with a shorthand so lightweight it adds zero memory overhead. Zero. Which sounds reckless until you look at how they keep the math honest.
They don’t just dump this stripped-down data into the attention layer and hope for the best. There’s a specialized estimator sitting in the pipeline, acting like a careful translator. It takes your high-precision query and strategically balances it against those brutally simplified, low-precision vectors. The payoff is that the attention scores stay sharp. You know, the actual mechanism the model uses to figure out which tokens matter in context and which ones can safely get ignored
It’s a tightrope, obviously. Push the compression too far and the signal collapses. But QJL keeps the relationships intact while shedding the numerical baggage. And when every extra bit costs you latency and VRAM, that kind of shorthand stops being a neat academic trick. It’s just table stakes.
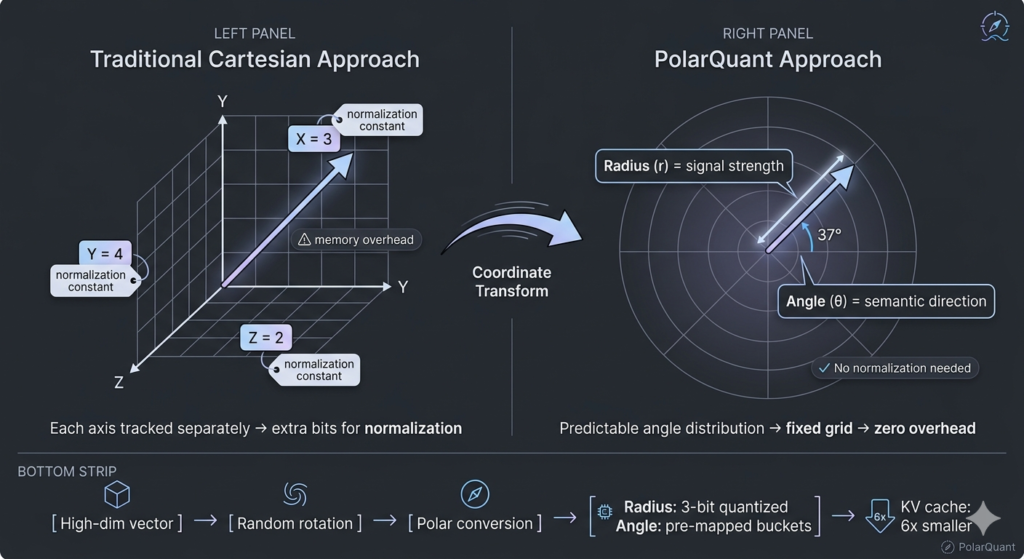
PolarQuant
If QJL handles the raw compression, PolarQuant is the one quietly fixing the geometry. Most quantization approaches just stare at vectors the standard Cartesian way: X, Y, Z, tracking distance along each axis. It works, sure, but it’s clunky. You end up dragging around extra memory just to keep the math stable between layers. PolarQuant sidesteps that by flipping the coordinate system entirely.
Think of it like giving directions across a grid. Instead of saying “go three blocks east, then four north,” you just say “five blocks out at a thirty-seven degree angle.” Same destination, cleaner path. In vector space, that splits everything into two intuitive pieces: radius (how strong the signal actually is) and angle (where it’s pointing, semantically speaking).
Here’s the part that actually matters for memory. Once those vectors get rotated into polar space, the angles don’t scatter randomly. They clump. They follow a tight, highly predictable pattern. And because that distribution is locked in, you can drop the expensive normalization step entirely. Traditional methods are stuck mapping data onto a shifting square grid, constantly recalculating boundaries as context changes. PolarQuant just drops it all onto a fixed circular grid. The edges are already known. You skip the overhead, save the bits, and let the model focus on attention instead of bookkeeping.
It’s a subtle shift, but it changes the math. No hidden normalization constants eating up your budget. No latency tax for keeping things aligned. Just a cleaner coordinate system doing the heavy lifting. Honestly, it’s one of those ideas that makes you wonder why we didn’t rotate the vectors sooner.
Experiments and results
Evaluated all three algorithms across standard long-context benchmarks including: LongBench, Needle In A Haystack, ZeroSCROLLS, RULER, and L-Eval using open-source LLMs (Gemma and Mistral). The experimental data demonstrate that TurboQuant achieves optimal scoring performance in terms of both dot product distortion and recall while simultaneously minimizing the key-value (KV) memory footprint.
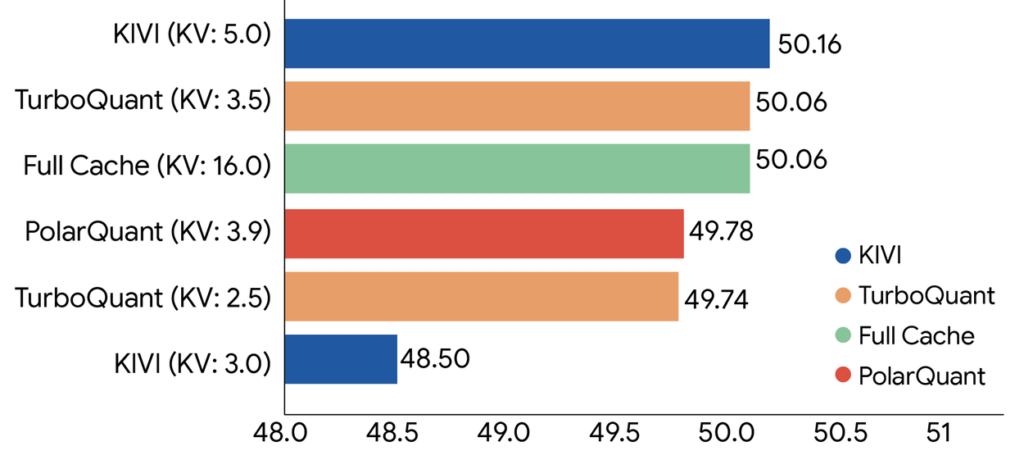
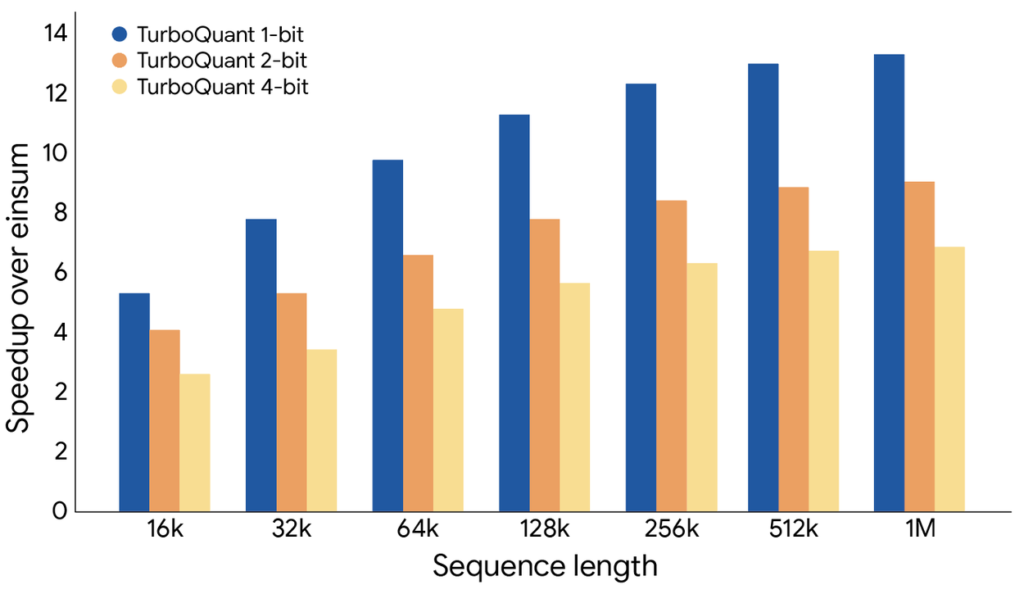
TurboQuant proved it can quantize the key-value cache to just 3 bits without requiring training or fine-tuning and causing any compromise in model accuracy, all while achieving a faster runtime than the original LLMs (Gemma and Mistral). It is exceptionally efficient to implement and incurs negligible runtime overhead. The following plot illustrates the speedup in computing attention logits using TurboQuant: specifically, 4-bit TurboQuant achieves up to 8x performance increase over 32-bit unquantized keys on H100 GPU accelerators.
Performance and Benchmarks
Additional data from the ICLR 2026 paper highlights its effectiveness across specific models:
| Metric | Full Precision (FP16) | TurboQuant (3.5-bit) | Improvement |
|---|---|---|---|
| Llama-3.1-8B LongBench | 50.06 | 50.06 | 0% Loss |
| Needle-in-a-Haystack | 0.997 | 0.997 | Perfect Retrieval |
| Vector Search Recall | Standard | Best-in-Class | Higher recall than PQ |
Industry Impact
When Google dropped the TurboQuant paper on March 25, 2026, it didn’t just spark a Twitter debate—it triggered a genuine market heart attack. Within 24 hours, the heavyweights of the memory industry were in freefall. Micron, Samsung, and SK Hynix saw their stocks tank, wiping out nearly $90 billion in market value in a single afternoon.
The investor logic was simple: if Google can compress AI memory by 6x with zero accuracy loss, the world suddenly needs 6x fewer expensive memory chips. In a market where High-Bandwidth Memory (HBM) was the golden goose, TurboQuant looked like the fox that just broke into the coop.
But if you look past the panic, the actual industry impact is a lot more nuanced:
- HBM Volatility : The most immediate shock hit the HBM market. Companies like SK Hynix had been riding a massive wave because AI models were literally outgrowing the GPUs they ran on. TurboQuant’s ability to shrink the KV cache from 16-bit to 3-bit basically told the market that software had finally found a way to “download more RAM.”
- Consumer GPU Revolution : For cloud providers, this is a massive win for density. If you can pack 6x more concurrent users onto the same NVIDIA H100 cluster, your profit margins on AI serving don’t just move—they skyrocket.
- Jevons Paradox in Real Time : While the initial reaction was “efficiency = less demand,” the counter-argument is the Jevons Paradox. By making inference 8x faster and 6x cheaper, Google hasn’t actually killed the memory market; they’ve potentially made it explode. When things get cheaper, we don’t just use less of them—we find a thousand new ways to use more of them.
- Local holy grail : This is where the real shift is happening. By slashing the memory footprint, TurboQuant makes it possible to run sophisticated, long-context models directly on your phone or laptop without needing a constant link to a data center. It’s the move from “Cloud AI” to “True Edge AI.”
Anyway, the irony of the whole RaBitQ drama is that while the academic world is arguing about who gets the credit, the financial world has already moved on to pricing in the era of “Extreme Compression.”
Honestly, the memory chip sell-off was likely a massive overreaction—a knee-jerk response from investors looking for any excuse to take profits after a two-year bull run. But it proved one thing: in 2026, a single PDF from a research lab can be more disruptive than a decade of hardware manufacturing.
We’re moving into an era where “software-defined memory” is just as important as the silicon itself. The question now isn’t whether we’ll need fewer chips, but how much more we can squeeze out of the ones we already have. Look, the Ferrari-versus-bicycle benchmarking scandal might leave a stain on the paper’s reputation, but for the industry, the genie is already out of the bottle. High-efficiency quantization is the new baseline.
The “RaBitQ” Controversy
The numbers were pretty.
Maybe too pretty.When Google dropped TurboQuant on March 25, the headlines were exactly what the market wanted to hear: 6x memory compression and 8x speedups without the usual accuracy tax. It looked like a total win—so much so that it wiped nearly $90 billion off memory stocks like Micron and Western Digital in a single afternoon. But as the dust settles, a much uglier conversation is bubbling up around an earlier method called RaBitQ.
Honestly, it’s a mess.What we’re seeing here is a classic case of how “state-of-the-art” claims can be manufactured if you’re willing to tie your opponent’s shoelaces together before the race starts. Jianyang Gao, the researcher behind RaBitQ, didn’t just stumble onto some discrepancies; he brought a paper trail showing that Google’s team was asking him for help debugging his code over a year ago.Look, if you just want the cliff notes on why the research community is currently on fire, here is the breakdown:
- The Rigged Race: TurboQuant was benchmarked on a high-end NVIDIA A100 GPU. They “tested” the competing RaBitQ on a single-core CPU with multithreading disabled. It’s like racing a Ferrari against a bicycle and then bragging about the lap time
- .The “Borrowed” Foundation: Both methods lean on the same mathematical trick—random rotations—to prep data for compression. TurboQuant framed this as its own breakthrough (“PolarQuant”), largely ignoring the fact that RaBitQ had already established this playbook.
- The Theoretical Dig: Google’s paper labeled RaBitQ’s math as “suboptimal” and “loose.” The problem? RaBitQ’s authors had already mathematically proven it hits the optimal limit, and they allegedly told Google this via email months before the paper was even submitted to ICLR.
- The Paper Trail: This isn’t just a misunderstanding. Emails from early 2025 show Google authors were intimately familiar with RaBitQ’s inner workings while they were developing TurboQuant, yet they still relegated the comparison to an appendix.
It’s not just academic drama for the sake of it. In a field moving this fast, we’re all standing on someone’s shoulders, but the unspoken rule is that you’re supposed to acknowledge whose shoulders they are before you start dancing.
Beyond the math, there’s a deeper issue here regarding the “Google effect.” When a giant like Google Research publishes a paper, it carries an immense amount of gravity. It moves markets. It dictates which technologies get baked into the chips we’ll be using in 2028. If the benchmarks are skewed—even if the underlying engineering is actually decent—it poisons the well for everyone else.
So, where does that leave us?
As of this week, the ICLR chairs have been looped in, and the drama has spilled out of private emails and into the open on GitHub and Reddit. Google’s defense is essentially that “random rotation is a standard technique,” which is technically true, but it misses the point. The issue isn’t whether the math is “standard”; it’s whether you can honestly claim a 10x leap over a predecessor you intentionally handicapped in your testing.
Ultimately, this controversy is a necessary wake-up call. If we can’t trust the metrics in the papers that are literally reshaping the global economy, we’re building the future of AI on sand. It’s a reminder that in the rush to be first, “fair” is often the first thing to get compressed.What’s your take—is this just a case of corporate sharp elbows, or is the whole AI benchmarking culture fundamentally broken?

hi